{kind=link}
SeleniumによるWebブラウザでもスクレイピングはできるのですが、SeleniumはWebブラウザ操作のためのものですから、より実践的にスクレイピングをしたい場合はBeautiful Soupを使ったスクレイピングがおすすめです。
スクレイピングは様々な場面で役に立つ技術なので、是非とも使えるようにしたいところです。
Beautiful Soupを使ったスクレイピングのやり方
まずはパッケージをインストールします。Beatutiful SoupはWebへアクセスする機能がありません。そのため Requests ライブラリを使ってインターネット上のWebへアクセスしXMLファイルやHTMLファイルをダウンロードします。
python -m pip install beautifulsoup4 python -m pip install requests
最初の導入:タイトルを取得する
それでは一番簡単な例としてYahooにアクセスして<title>タグからタイトルを取得して表示してみます
Beautiful Soupは次のようにして使います。
BeautifulSoup(解析したいXML/HTML, パーサー)
パーサーはXMLやHTMLを解析するライブラリです。今回は標準装備の html.parser を使いますが他にも利用できます。
| パーサー | 説明 |
| html.parser | 標準装備のパーサー |
| xml | 高速XMLパーサー |
| lxml | 高速HTMLパーサー |
| html5lib | HTML5対応パーサー |
from bs4 import BeautifulSoup
import requests
# アクセスするURL
url = "https://yahoo.co.jp/"
# WEB接続する
res = requests.get(url)
# BeautifulSoupで解析
soup = BeautifulSoup(res.text, "html.parser")
# タイトルを表示
print(soup.find("title").text)soup.find で「<title>~</title>」を探しています。詳しくは後述しますが、このようにタグを使ってデータを抽出する事ができます。
このスクリプトを実行するとタイトルが表示されます。
$ python get-title.py Yahoo! JAPAN
これが基本です。
CSSセレクタ、HTMLタグを使ったデータの抽出方法
Beautiful Soupは必要なデータを抽出するための方法がいくつかあります。
- selectメソッドを使いCSSセレクタで抽出するデータを指定する
- findやfind_allメソッドを使いHTMLタグで抽出するデータを指定する
- HTML階層を辿って抽出するデータを指定する
selectメソッドを使いCSSセレクタで抽出するデータを指定する
CSSセレクタを使うには、取得したい箇所を調べる必要があります。Yahooのトピックス一覧を例に実践してみましょう。
赤枠で囲ったITトピックススの1箇所を抽出してみます。
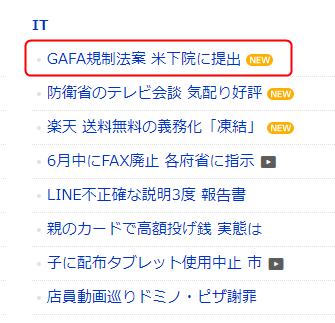
Chromeを立ち上げて Yahooのトピックス一覧 へアクセスし、抽出したい箇所を右クリックしてから「検証」をクリックします。
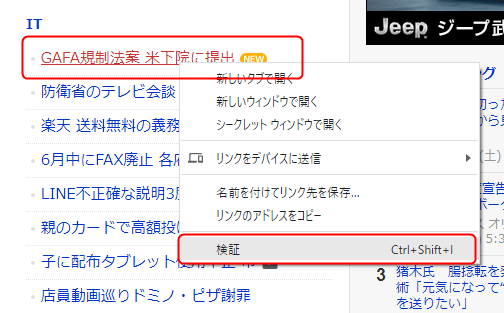
検証をクリックするとこのように開発者ツールが立ち上がって該当箇所のエレメントがマーキングされた状態になります。

このマーキングされた箇所にマウスカーソルをもっていき右クリックします。そして「Copy」から「Copy selector」をクリックしてください。
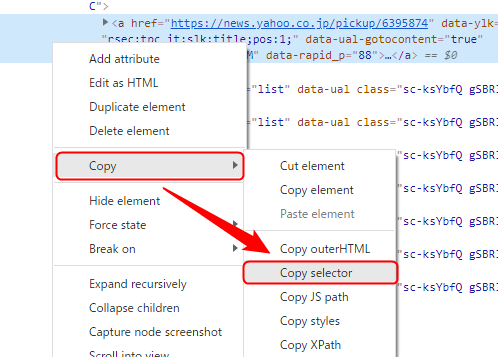
これでクリップボードにCSSセレクタがコピーされます。
#contentsWrap > div > div:nth-child(6) > div > ul > li:nth-child(1) > a
それでは抽出できるか確認しましょう。
from bs4 import BeautifulSoup import requests # アクセスするURL url = "https://news.yahoo.co.jp/topics" # WEB接続する res = requests.get(url) # BeautifulSoupで解析 soup = BeautifulSoup(res.text, "html.parser") # CSSセレクタで抽出箇所を指定 css_selector = "#contentsWrap > div > div:nth-child(6) > div > ul > li:nth-child(1) > a" # トピックスを抽出 elements = soup.select(css_selector) print(elements[0].text) print(elements[0].attrs['href'])
わたしの環境では以下のようにトピックスのタイトルとURLが抽出できました。
$ python css-selector.py GAFA規制法案 米下院に提出 https://news.yahoo.co.jp/pickup/6395874
それではITトピックスの一覧すべてを取得するにはどうすれば良いのでしょうか。
その場合はCSSセレクタを以下のように変更します。
css_selector = "#contentsWrap > div > div:nth-child(6) > div > ul > li:nth-child(1) > a" ↓ css_selector = "#contentsWrap > div > div:nth-child(6) > div > ul > li > a"
これでITトピックスの一覧がすべて抽出できます。次のようにして一覧を表示させてみましょう。
from bs4 import BeautifulSoup
import requests
# アクセスするURL
url = "https://news.yahoo.co.jp/topics"
# WEB接続する
res = requests.get(url)
# BeautifulSoupで解析
soup = BeautifulSoup(res.text, "html.parser")
# CSSセレクタで抽出箇所を指定
css_selector = "#contentsWrap > div > div:nth-child(6) > div > ul > li > a"
# トピックスを抽出
elements = soup.select(css_selector)
for topic in elements:
print(topic.text, " ", end="")
print(topic.attrs["href"])このスクリプトを実行すると次のようにITトピックスの一覧がすべて表示されます。
$ python css-selector-it-topics.py GAFA規制法案 米下院に提出 https://news.yahoo.co.jp/pickup/6395874 防衛省のテレビ会談 気配り好評 https://news.yahoo.co.jp/pickup/6395858 楽天 送料無料の義務化「凍結」 https://news.yahoo.co.jp/pickup/6395818 6月中にFAX廃止 各府省に指示 https://news.yahoo.co.jp/pickup/6395805 LINE不正確な説明3度 報告書 https://news.yahoo.co.jp/pickup/6395804 親のカードで高額投げ銭 実態は https://news.yahoo.co.jp/pickup/6395776 子に配布タブレット使用中止 市 https://news.yahoo.co.jp/pickup/6395669 店員動画巡りドミノ・ピザ謝罪 https://news.yahoo.co.jp/pickup/6395634
同じ要領で、ITトピックスだけでなくすべてのトピックスを抽出するにはどうすれば良いのでしょうか。
再度CSSセレクタを次のように変更します。
css_selector = "#contentsWrap > div > div:nth-child(6) > div > ul > li > a" ↓ css_selector = "#contentsWrap > div > div > div > ul > li > a"
上記の1行の他に変更箇所はありません。
from bs4 import BeautifulSoup
import requests
# アクセスするURL
url = "https://news.yahoo.co.jp/topics"
# WEB接続する
res = requests.get(url)
# BeautifulSoupで解析
soup = BeautifulSoup(res.text, "html.parser")
# CSSセレクタで抽出箇所を指定
css_selector = "#contentsWrap > div > div > div > ul > li > a"
# トピックスを抽出
elements = soup.select(css_selector)
for topic in elements:
print(topic.text, " ", end="")
print(topic.attrs["href"])このスクリプトを実行すると以下のようにすべてのトピックス一覧を抽出する事ができます。
$ python css-selector-all-topics.py 時短協力金の支給率 地域で大差 https://news.yahoo.co.jp/pickup/6395904 日韓首脳があいさつ、初対面 https://news.yahoo.co.jp/pickup/6395902 実習生失踪 一部受け入れ停止へ https://news.yahoo.co.jp/pickup/6395903 首相 お手上げ発言と単純な発想 https://news.yahoo.co.jp/pickup/6395895 大規模接種 全国から電話予約可 https://news.yahoo.co.jp/pickup/6395849 安倍氏 表舞台復帰の「野望」 https://news.yahoo.co.jp/pickup/6395855 出頭要請のロシア側職員が出国 https://news.yahoo.co.jp/pickup/6395888 秘書検定 古い企業変わらぬ現実 https://news.yahoo.co.jp/pickup/6395886
findやfind_allメソッドを使いHTMLタグで抽出するデータを指定する
findやfind_allを使うとHTMLタグで抽出するデータを指定できます。findとfind_allの違いは次の通りです。
| find() | 最初に見つかったHTMLタグを取得する |
| find_all() | 見つかったすべてのHTMLタグを取得する |
それではYahooのトピックス一覧からすべてのトピックスとURLを抽出してみます。
from bs4 import BeautifulSoup import requests # アクセスするURL url = "https://news.yahoo.co.jp/topics" # WEB接続する res = requests.get(url) # BeautifulSoupで解析 soup = BeautifulSoup(res.text, "html.parser") # HTMLタグで抽出箇所を指定 html_tag = "a" # トピックスを抽出 elements = soup.find_all(html_tag) print(elements)
このスクリプトを実行するとすべてのaタグを抽出するのでこのように不要なものまで含まれてしまいます。
$ python fetch-html-tag-1.py [<a data-redirectadclick="" data-ylk="slk:h_ytop;pos:0" href="https://www.yahoo.co.jp/" id="msthdYtop">Yahoo! JAPAN</a>, <a data-redirectadclick="" data-ylk="slk:h_hlp;pos:0" href="https://www.yahoo-help.jp/app/home/service/news/" id="msthdHelp">ヘルプ</a>, <a data-redirectadclick="" data-ylk="slk:h_srvtop;pos:0" href="https://news.yahoo.co.jp/" id="msthdLogo"> <img alt="Yahoo!ニュース" height="34" src="https://s.yimg.jp/c/logo/f/2.0/news_r_34_2x.png" width="206"/> </a>, <a class="b" data-redirectadclick="" data-ylk="slk:h_regyid;pos:0" href="https://account.edit.yahoo.co.jp/registration?.intl=jp&.done=https%3A%2F%2Fnews.yahoo.co.jp%2Ftopics&.src=news" id="msthdReg">新規取得</a>, <a class="b" data-redirectadclick="" data-ylk="slk:h_login;pos:0"
これでは使い物になりません。そこで抽出条件を加えます。
Yahooのトピックス一覧のソースを見ると、どれも「https://news.yahoo.co.jp/pickup/数字」というフォーマットになっています。これを利用しましょう。
抽出条件に正規表現を加えれば余計なデータを除去できるはずです。そのため正規表現を扱う事ができるreモジュールを使います。
from bs4 import BeautifulSoup
import requests
import re
# アクセスするURL
url = "https://news.yahoo.co.jp/topics"
# WEB接続する
res = requests.get(url)
# BeautifulSoupで解析
soup = BeautifulSoup(res.text, "html.parser")
# トピックスを抽出
elements = soup.find_all(href=re.compile("https://news.yahoo.co.jp/pickup/[0-9]+"))
print(elements)正規表現による検索は以下のようにしています。
elements = soup.find_all(href=re.compile("https://news.yahoo.co.jp/pickup/[0-9]+"))このスクリプトを実行すると次のように取得できます。
$ python fetch-html-tag-2.py [<a class="sc-hmzhuo hkqpwM" data-ual-gotocontent="true" data-ylk="rsec:tpc_dom;slk:title;pos:1;" href="https://news.yahoo.co.jp/pickup/6395904">時短協力金の支給率 地域で大差<span aria-label="NEW" class="labelIcon labelIcon-NEW"></span></a>, <a class="sc-hmzhuo hkqpwM" data-ual-gotocontent="true" data-ylk="rsec:tpc_dom;slk:title;pos:2;" href="https://news.yahoo.co.jp/pickup/6395902">日韓首脳があいさつ、初対面<span aria-label="NEW" class="labelIcon labelIcon-NEW"></span></a>, <a class="sc-hmzhuo hkqpwM" data-ual-gotocontent="true" data-ylk="rsec:tpc_dom;slk:title;pos:3;" href="https://news.yahoo.co.jp/pickup/6395903">実習生失踪 一部受け入れ停止へ<span aria-label="NEW" class="labelIcon labelIcon-NEW"></span></a>, <a class="sc-hmzhuo hkqpwM" data-ual-gotocontent="true" data-ylk="rsec:tpc_dom;slk:title;pos:4;" href="https://news.yahoo.co.jp/pickup/6395895">首相 お手上げ発
最初のトピックスとURLを抽出するには次のようにします。
print(elements) ↓ print(elements[0].contents[0]) print(elements[0].attrs["href"])
この要領で elements[1]、elements[2]と進めていけばいいので、次のように修正してすべてのトピックスを見やすく抽出します。
from bs4 import BeautifulSoup
import requests
import re
# アクセスするURL
url = "https://news.yahoo.co.jp/topics"
# WEB接続する
res = requests.get(url)
# BeautifulSoupで解析
soup = BeautifulSoup(res.text, "html.parser")
# トピックスを抽出
elements = soup.find_all(href=re.compile("https://news.yahoo.co.jp/pickup/[0-9]+"))
for topic in elements:
print(topic.contents[0], " ", end="")
print(topic.attrs["href"])$ python python fetch-html-tag-3.py 時短協力金の支給率 地域で大差 https://news.yahoo.co.jp/pickup/6395904 日韓首脳があいさつ、初対面 https://news.yahoo.co.jp/pickup/6395902 実習生失踪 一部受け入れ停止へ https://news.yahoo.co.jp/pickup/6395903 首相 お手上げ発言と単純な発想 https://news.yahoo.co.jp/pickup/6395895 大規模接種 全国から電話予約可 https://news.yahoo.co.jp/pickup/6395849 安倍氏 表舞台復帰の「野望」 https://news.yahoo.co.jp/pickup/6395855 出頭要請のロシア側職員が出国 https://news.yahoo.co.jp/pickup/6395888 秘書検定 古い企業変わらぬ現実 https://news.yahoo.co.jp/pickup/6395886
まとめ
selectメソッドとfind_allメソッドによるスクレイピングの超基本をご紹介しました。
本格的なクローリングとなるとリンクを辿って更に別のページへ、そこから別のページへ、と続くわけですが、それはまた別のテクニックが必要となるので最初はひとつのページから目的の情報を抽出できれば十分だと思います。
今回URLを抽出しましたので、画像などのファイルをダウンロードする場合は requests.get(画像URL) のようにしてからファイルに書き込めば良いでしょう。
クローリングについて優しく解説しているのは「シゴトがはかどる Python自動処理の教科書」で、初心者でもつまずく事なく読める良書です。更に本格的にスクレイピングを学びたい場合は「Pythonクローリング&スクレイピング」を参考にすると良いかと思います。
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント