{kind=link}
PythonでWebブラウザを自由に操作できるようになると普段Webブラウザで作業をしている亊が自動化できるようになります。
またスクリーンショットも撮れるので、インフラエンジニアが動作確認のため大量のWebページにアクセスしてスクリーンショットを取得するなんて手間な作業も自動化できます。
Webブラウザを操作するといえば有名なのが「Selenium」です。これを使っていきましょう。
目次
Seleniumを使い始める準備
Seleniumをインストール
まずはSeleniumをインストールします。
python -m pip install selenium
ドライバをインストール
次にドライバをインストールします。注意点としてお使いのWebブラウザのバージョンに合わせたドライバが必要です。
https://sites.google.com/a/chromium.org/chromedriver/downloads
わたしが使っているChromeのバージョンは 91.0.4472.101 です。
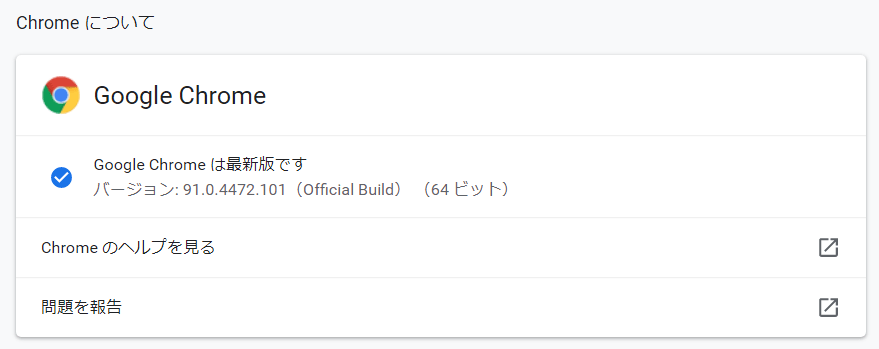
Chrome 91のドライバをダウンロードすれば良さそうです。
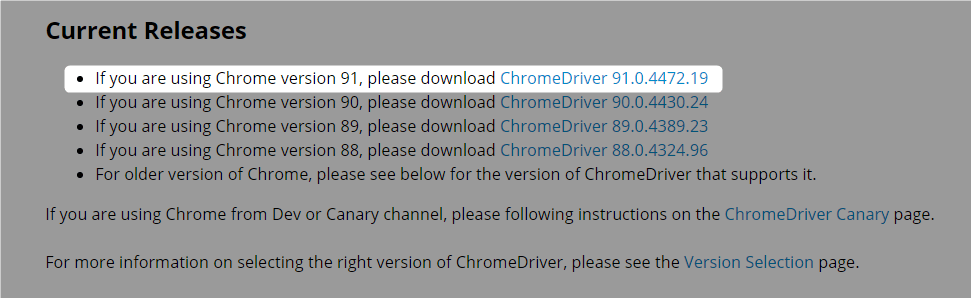
このドライバをパスの通ったフォルダに配置するのですが、ちょっと待ってください。この方法はとても面倒です。
webdriver_managerをインストール
Webブラウザがバージョンアップされる度にドライバを差し替えるというのは面倒です。そこで「webdriver_manager」というものを使います。webdriver_managerはWebブラウザのバージョンに合わせて適切なドライバを自動的にダウンロードしてくれる優れものです。これを使わない手はありません。
次のようにしてインストールします。
python -m pip install webdriver-manager
次のようなPythonスクリプトを作成して実行し、ドライバがダウンロードされる亊を確認してみます。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://google.com')このスクリプトを実行してみましょう。
$ python selenium-test.py ====== WebDriver manager ====== Current google-chrome version is 91.0.4472 Get LATEST driver version for 91.0.4472 There is no [win32] chromedriver for browser 91.0.4472 in cache Get LATEST driver version for 91.0.4472 Trying to download new driver from https://chromedriver.storage.googleapis.com/91.0.4472.19/chromedriver_win32.zip Driver has been saved in cache [C:\Users\name.wdm\drivers\chromedriver\win32\91.0.4472.19] DevTools listening on ws://127.0.0.1:50523/devtools/browser/ea7f5ed0-2055-443f-8521-c863ecf876d6 [11228:8436:0611/175023.245:ERROR:device_event_log_impl.cc(214)] [17:50:23.244] Bluetooth: bluetooth_adapter_winrt.cc:1072 Getting Default Adapter failed.
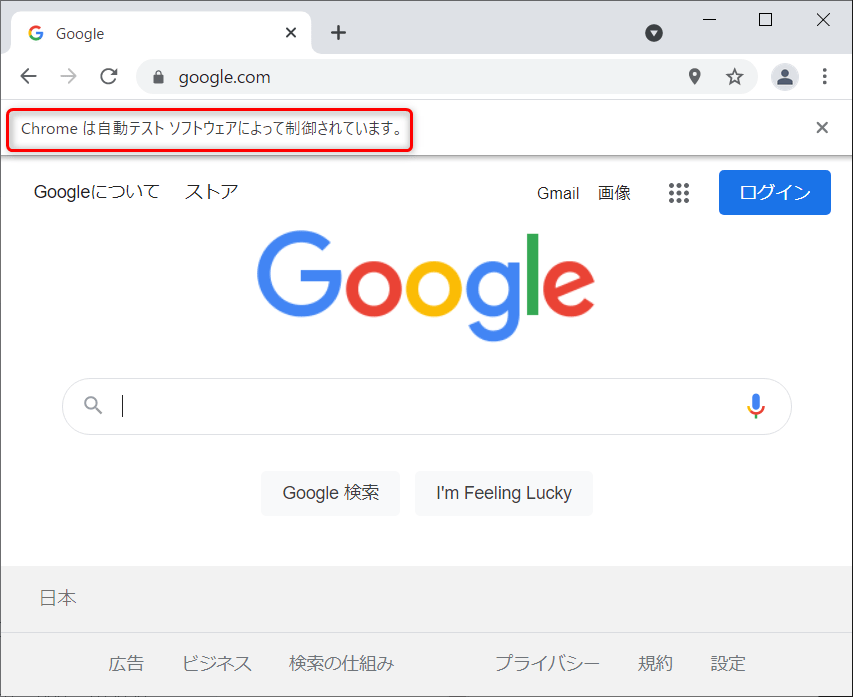
ダウンロードされていますね。そしてブラウザが自動的に立ち上がるはずです。
「Chrome は自動テスト ソフトウェアによって制御されています。」と表示されているのは、Seleniumで制御しているためです。
ドライバをインストールするとキャッシュするので同じドライバを何度もダウンロードしてインストールするなんて亊はしませんからご安心ください。
Webブラウザ別ドライバ自動更新方法
本記事ではGoogle Chromeを使用していますが、他のWebブラウザでもSeleniumは使用できます。以下にWebブラウザ別の使用方法をまとめます。
Google Chrome
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://google.com')Microsoft Edge
from selenium import webdriver
from webdriver_manager.microsoft import EdgeChromiumDriverManager
driver = webdriver.Edge(EdgeChromiumDriverManager().install())
driver.get('https://google.com')Firefox
from selenium import webdriver
from webdriver_manager.firefox import GeckoDriverManager
driver = webdriver.Firefox(executable_path=GeckoDriverManager().install())
driver.get('https://google.com')Opera
from selenium import webdriver
from webdriver_manager.opera import OperaDriverManager
driver = webdriver.Opera(executable_path=OperaDriverManager().install())
driver.get('https://google.com')Internet Explorer
from selenium import webdriver
from webdriver_manager.microsoft import IEDriverManager
driver = webdriver.Ie(IEDriverManager().install())
driver.get('https://google.com')SeleniumによるWebブラウザの操作方法
SeleniumでGoogle検索してみる
google.comへアクセスするスクリプトは先ほどドライバが自動的にダウンロードされるか確認する際に作成しているので、今度はGoogleで「Selenium」と検索してから3秒待機して、それからWebブラウザを閉じてみましょう。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from webdriver_manager.chrome import ChromeDriverManager
import time
# 検索文字を入力するためのXPath
xpath = "/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input"
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://google.com')
# タイムアウトを10秒に設定
wait = WebDriverWait(driver, 10)
# すべての要素が表示されるまで待機
element = wait.until(expected_conditions.visibility_of_all_elements_located)
# 検索文字列を入力
input = driver.find_element_by_xpath(xpath)
input.send_keys("selenium")
input.submit()
# 3秒間待機してクローズ
time.sleep(3)
driver.quit()selenium を使うコツは要素(Element)を調べて、そこに文字列を送ったりボタンを押すのですが、要素を調べるのがわたしは苦手です。
ですのでXPathを指定して検索文字列を送り込んでいます。
# 検索文字を入力するためのxpath xpath = "/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input" … input = driver.find_element_by_xpath(xpath)
このXPathの調べ方ですが、とても簡単です。
XPathの調べ方
Googleのページを例にしましょう。GoogleのページでF12 ボタンを押して開発者ツールを起動してください。
そうしましたら、検索ボックスをマウスでフォーカスしてから右クリックします。そして「検証」をクリックします。
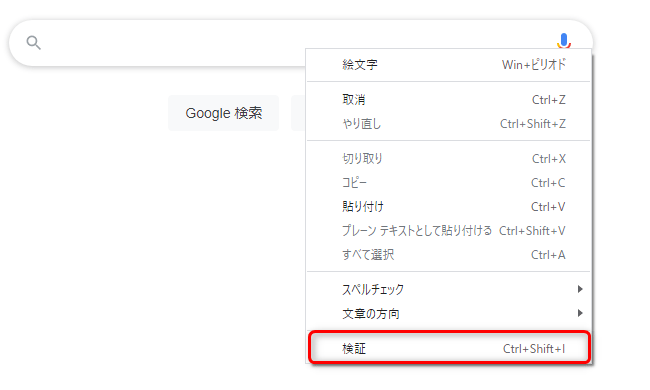
すると以下のように一部の色が変わります。
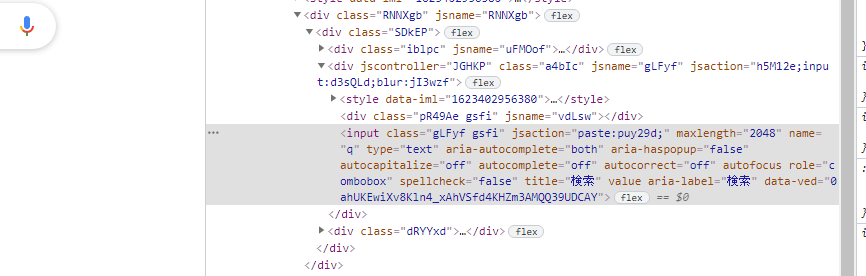
次にこの色が変わった箇所で右クリックします。そして以下のように「Copy」から「Copy XPath」をクリックします。これでクリップボードにXPathがコピーされます。
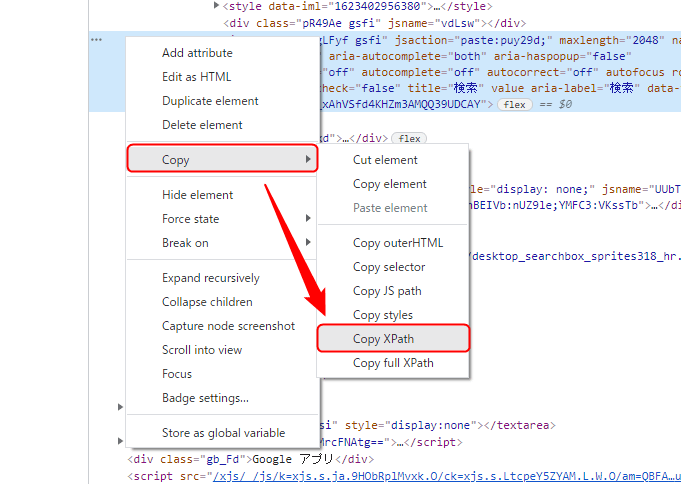
クラス名やIDの取得がうまく行かない場合はXPathを試してみてください。
参考リンク:https://kurozumi.github.io/selenium-python/locating-elements.html#locating-by-xpath
ページが表示されるまで待機する
Sleepで待機させるのは簡単なのですが、確実に動作させるには目的の要素が表示されるまで待機する亊が大事です。
これはとても重要です。
今回は「visibility_of_all_elements_located」を使っており、これは全要素が表示されるまで待つため場合によっては動作が遅くなりますが安心確実な方法です。
# すべてのページが表示されるまで待機 element = wait.until(expected_conditions.visibility_of_all_elements_located)
Seleniumでの待機方法は次のようなものがあります。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get("https://google.com/")
# Webドライバーのタイムアウト時間を10秒に設定
wait = WebDriverWait(driver, 10)
# 指定した文字列がページタイトルに含まれるまで待機
element = wait.until(expected_conditions.title_contains("タイトル名"))
# 指定した要素がDOM上に現れ, かつheight・widthが0以上になるまで待機
element = wait.until(expected_conditions.visibility_of_element_located(By.ID, 'id属性値'))
# ページの全要素がDOM上に現れ, かつheight・widthが0以上になるまで待機
element = wait.until(expected_conditions.visibility_of_all_elements_located)
# 指定した要素がクリックできる状態になるまで待機
element = wait.until(expected_conditions.element_to_be_clickable(By.XPASS, "XPath")) Webブラウザを表示させずに操作する(ヘッドレスモード)
ここまでの解説はWebブラウザを起動して操作していました。しかし、必ずしもWebブラウザを表示させる必要はないはずです。自動化の際はむしろ不要です。
そのようなときのためにヘッドレスモードが使えます。
ヘッドレスモードはWebブラウザを表示する亊なく操作する方法ですが、何も難しい亊はありません。次のようにオプションを付けるだけです。
元のコード:
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://google.com')ヘッドレスモードに変更:
# オプション設定
options = webdriver.ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
driver.get('https://google.com')これだけで動きます。簡単ですね。しかもWebブラウザを表示していないのにスクリーンショットが撮れます。とても便利です。
ちなみにヘッドレスモードで動作させるとUser-Agentに「Headless」という文字列が入ります。ヘッドレスモードにしたらうまく動かない、という場合は接続先がヘッドレスモードを検知している可能性があります。
その場合はUser-Agentを変更する事で対処可能です。SeleniumでUser-Agentを変えるには次のようにします。
# User-Agent
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36"
# オプション設定
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument('--user-agent=' + user_agent)
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
driver.get('https://google.com')スクリーンショットを撮る
Webサイトにアクセスしてスクリーンショットを撮る場面は少なからずあります。わたしは数百のサイトにアクセスしてスクリーンショットを撮るという仕事をした亊があります大変な作業でした。
こういった亊は簡単に自動化できます。
Seleniumには save_screenshot メソッドが用意されており、これを使えば誰でも簡単にスクリーンショットを撮る亊ができます。
それでは先ほどのSeleniumについてGoogle検索するスクリプトをベースに、スクリーンショットを撮るように修正を加えます。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from webdriver_manager.chrome import ChromeDriverManager
import time
# 検索文字を入力するためのxpath
xpath = "/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input"
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://google.com')
# ウィンドウサイズを設定
driver.set_window_size(1024, 768)
# タイムアウトを10秒に設定
wait = WebDriverWait(driver, 10)
# すべてのページが表示されるまで待機
element = wait.until(expected_conditions.visibility_of_all_elements_located)
# 検索文字列を入力
input = driver.find_element_by_xpath(xpath)
input.send_keys("selenium")
input.submit()
# すべてのページが表示されるまで待機
element = wait.until(expected_conditions.visibility_of_all_elements_located)
# スクリーンショットを撮る
driver.save_screenshot("search-selenium.png")
# 3秒間待機してクローズ
time.sleep(3)
driver.quit()スクリーンショットを撮るためにウィンドウサイズを変更しました。次のようにして1024x768に設定します。
# ウィンドウサイズを設定 driver.set_window_size(1024, 768)
次に、検索した後にすべての要素が表示されるまで待機します。
# すべてのページが表示されるまで待機 element = wait.until(expected_conditions.visibility_of_all_elements_located)
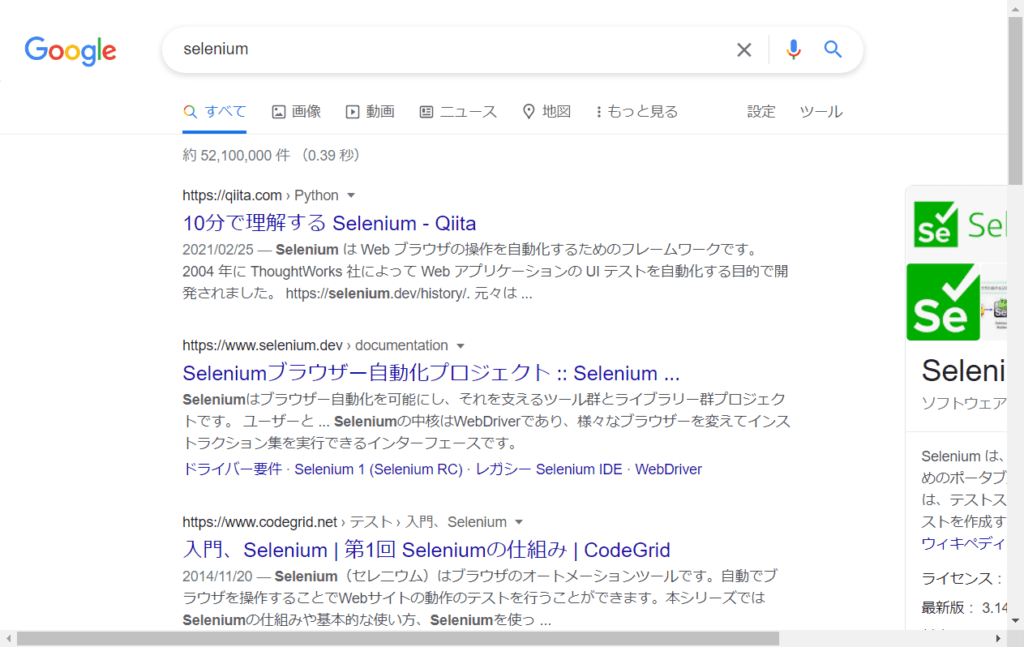
すべて表示されたらスクリーンショットを撮ります。
# スクリーンショットを撮る
driver.save_screenshot("search-selenium.png")これでスクリーンショットが撮れているはずです。フォルダを見るとファイルがありました。
ページ全体のスクリーンショットを撮る
先ほどの例ではウィンドウサイズを1024x768に設定してスクリーンショットを撮りました。
しかしページ全体のスクリーンショットが必要となる亊もあるでしょう。その方法を解説します。
まず、サイトにアクセスしてからJavascriptを使ってページのサイズを取得します。そしてウィンドウサイズを変更してからスクリーンショットを撮る、という流れになります。
検索結果のスクリーンショットを撮るスクリプトを修正してページ全体のスクリーンショットを撮ってみましょう。
変更は以下の4点です。
- ヘッドレスモードにする
- JavaScriptでページサイズを取得する
- ページサイズを変更する
- スリープ削除(画面は見えないので不要)
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from webdriver_manager.chrome import ChromeDriverManager
import time
# 検索文字を入力するためのxpath
xpath = "/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input"
# オプション設定
options = webdriver.ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
driver.get('https://google.com')
# タイムアウトを10秒に設定
wait = WebDriverWait(driver, 10)
# すべてのページが表示されるまで待機
element = wait.until(expected_conditions.visibility_of_all_elements_located)
# 検索文字列を入力
input = driver.find_element_by_xpath(xpath)
input.send_keys("selenium")
input.submit()
# すべてのページが表示されるまで待機
element = wait.until(expected_conditions.visibility_of_all_elements_located)
# ページのサイズを取得する
page_width = driver.execute_script("return document.body.scrollWidth;")
page_height = driver.execute_script("return document.body.scrollHeight;")
# ウィンドウサイズを設定
driver.set_window_size(page_width, page_height)
# スクリーンショットを撮る
driver.save_screenshot("search-selenium-full.png")
# クローズ
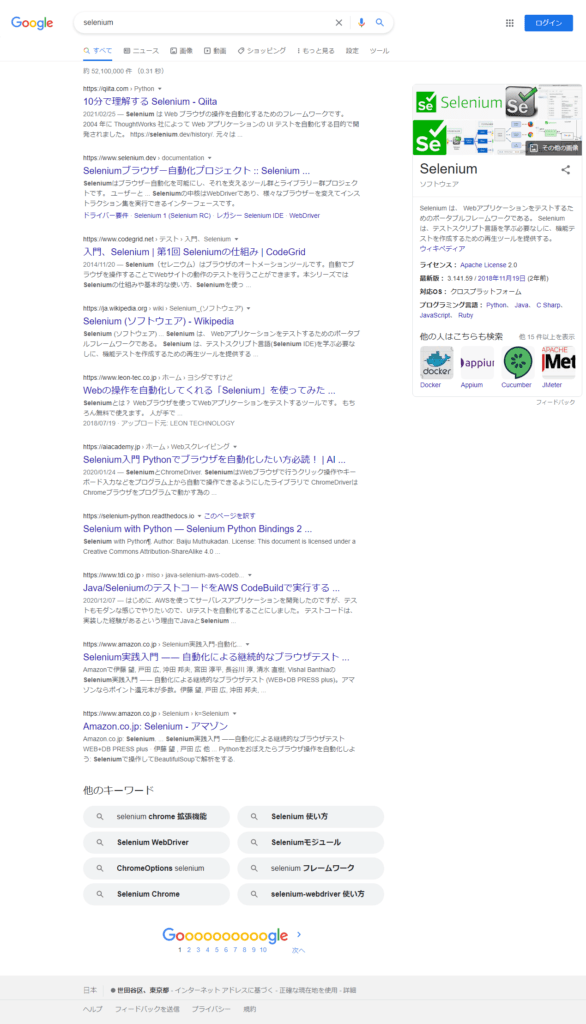
driver.quit()実行するとページ全体のスクリーンショットが撮れている亊を確認できます。
まとめ
Seleniumを使うと簡単にWebブラウザを操作できる亊が分かって頂けたかと思います。
Webブラウザを自動操作できるようになると業務効率化がますます進むでしょうから是非とも活用して頂きたいです。
自動化で業務効率化をしたいと思っている方は下の「シゴトがはかどる Python自動処理の教科書」が初心でも分かりやすい解説でとても参考になります。Seleniumにも触れておりおすすめの本です。更に本格的にクローリングやスクレイピングを実践したい方は「Pythonクローリング&スクレイピング」が大変おすすめです。
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
コメント